
Kristine Briones, Research Assistant at Young Lives discusses the new release of “constructed files” of all four of rounds of data which features about 200 variables selected from the Young Lives household and child surveys.
![]()
The Young Lives survey is an innovative long-term project investigating the changing nature of childhood poverty in four developing countries. The purpose of the project is to improve understanding of the causes and consequences of childhood poverty and examine how policies affect children’s well-being, in order to inform the development of future policy and to target child welfare interventions more effectively.
The Young Lives study aims to track the lives of 12,000 children over a 15-year period, surveyed once every 3-4 years. Round 1 of Young Lives surveyed two groups of children in each country, at 1 year old and 5 years old. Round 2 returned to the same children who were then aged 5 and 12 years old. Round 3 surveyed the same children again at aged 7-8 years and 14-15 years, and Round 4 surveyed them at 12 and 19 years old. Thus the younger children are being tracked from infancy to their mid-teens and the older children through into adulthood, when some will become parents themselves.
Here at Young Lives, we’ve just released “constructed files” of all four of our rounds of data which features about 200 variables selected from our household and child surveys. They are available to download from the UK Data Service.
The constructed files are combined sub-sets of variables from Rounds 1 to 4 of the Young Lives household and child surveys conducted in 2002, 2006, 2009, and 2013. One main constructed data file is available for each of the four countries. These are presented in a panel format and contain approximately 200 original and constructed variables, with the majority comparable across all three rounds. The Stata syntax (.do) files which have been used to create the constructed data files are also included for information. They provide access to variables mostly available in all 4 rounds and focus on:
- Child health and nutrition (includes data on height, weight, illness, etc.),
- Child education (includes data on school enrolment, test scores, etc.),
- Child time allocation (includes data on child’s hours spent on paid and unpaid labour, schooling, leisure, etc.),
- Child subjective well-being.
Also included in the data set are:
- Household standard of living (includes data on household measures of wealth such as housing quality, access to services, food and non-food expenditures, etc.),
- Household access to public programmes such as the Productive Safety Net Programme in Ethiopia and the National Rural Employment Guarantee Scheme in India,
- A list of economic, environmental, social, and health-related events/shocks that may have affected the household (we have more than 50 items across all rounds).
We also computed indicators of child health and household wealth using the existing data. Using the World Health Organisation (WHO) reference tables, z-scores were estimated from the children’s health information which were then used to compute for child malnutrition indicators (stunting, thinness, etc.). A household wealth index was also calculated by combining three living standard indicators: housing quality, access to services, and consumer durables. The indices were estimated consistently and are comparable across rounds.
To supplement analyses, also available are characteristics (age, gender, and education) of specific household members (household head, the child’s biological father and mother, and the child’s caregiver).
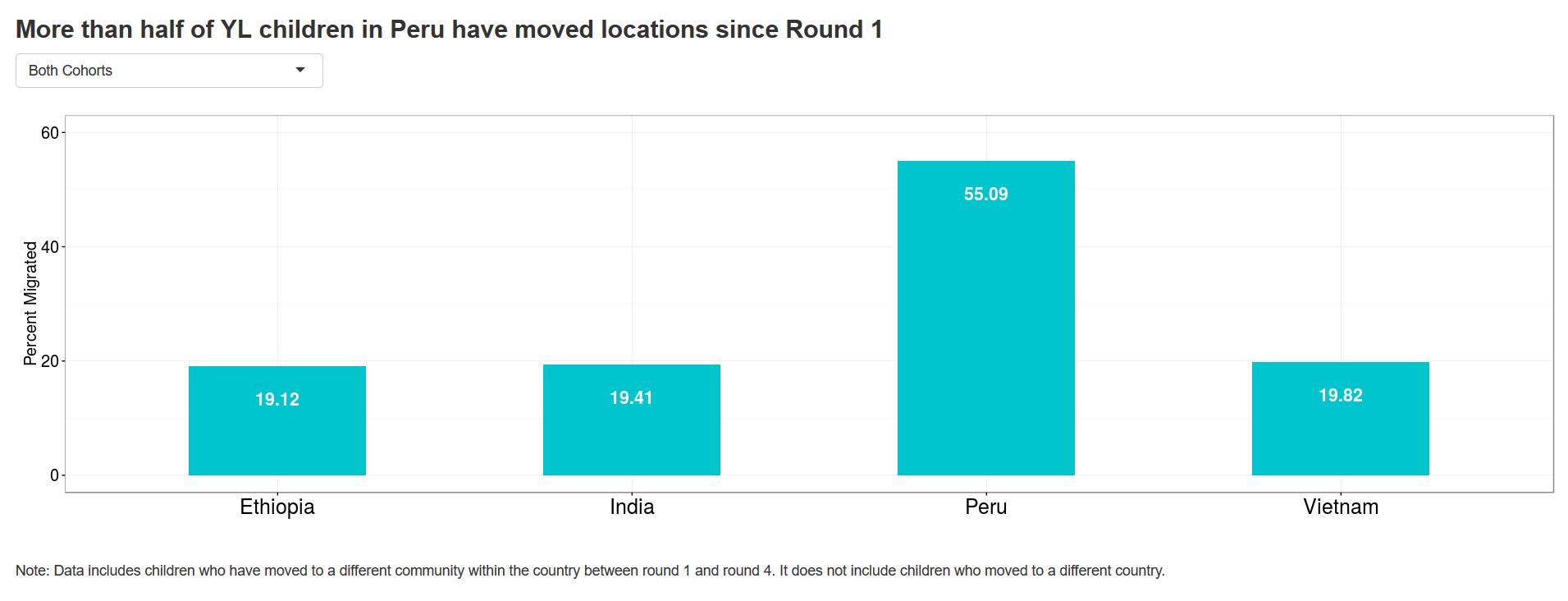
Since variables are merged into a single dataset, the constructed files are useful in tracking child outcomes in 4 periods throughout their childhood years (from age 1 to 12 years for the younger cohort and from 8 to 19 years for the older cohort) without difficulty. For example, the graph below shows the percentage of children who moved to a different community between rounds 1 and 4.
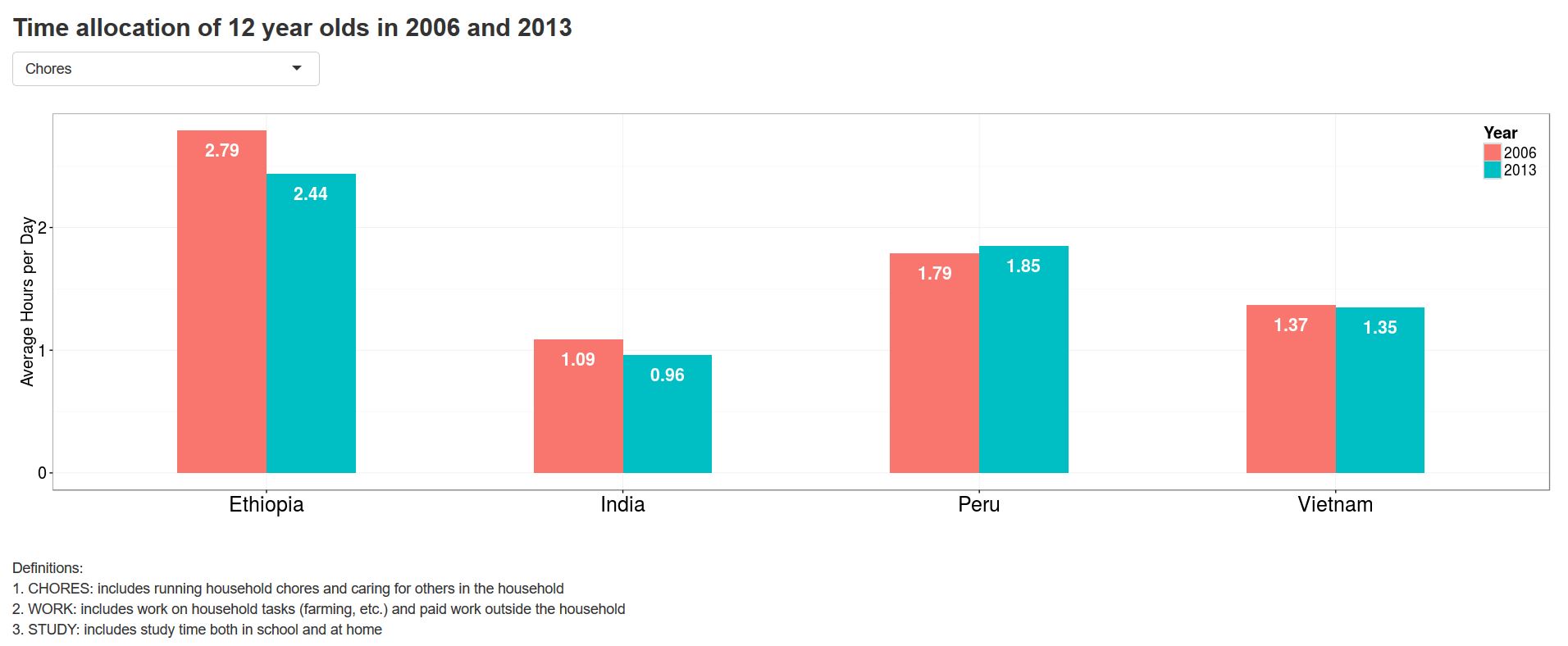
Young Lives follows children from two age groups and the constructed files can also be straightforwardly used to compare children of specific ages at different time periods. For example, 12-year old children (older cohort, round 2) in 2006 can be evaluated with 12-year olds (younger cohort, round 4) in 2013.
In cases where researchers feel the need to add more variables for their analysis, the constructed files can be merged with other Young Lives datasets by using the unique child ID. The complete rounds 1 to 4 survey data of Young Lives is also available to download from the UK Data Service.
The constructed files also come with a technical note which provides a detailed description of the variables. So download our data and run your analyses. Be sure to share your findings with us on Twitter @yloxford and Facebook.
Dear Christine,
Thank you very much for all your work and generosity in sharing the data.
I guess I am not the only one who tries to merge all the datasets from all five rounds “by using the unique child ID”. And maybe they encounter the same problem. I was just wondering if you have already a solution to this and could you kindly please help to merge all of the datasets from YoungLives Vietnam. The problem is the datasets in rounds 1,2,3 from Young Lives Vietnam use CHILDID while round 4 and5 use CHILDCODE. And they are different in many ways. Although I can add the Prefix “VN0” to the name of the CHILDCODE, many cases still do not fit with the CHILDID in their previous rounds. Therefore, I can not merge them all together.
I would appreciate it very much if you could show me how you identify the “unique child ID” in all rounds and merge them in one big dataset.
Thank you again. I wish you a nice start to the new week and I am looking forward to hearing from you.
Best regards,
Phuong Dinh