 Andreas Mastrosavvas introduces the Longitudinal Impossible Dataset, a tool that lets users generate metadata-based synthetic datasets mirroring the structure and coding schemes of the Office for National Statistics Longitudinal Study.
Andreas Mastrosavvas introduces the Longitudinal Impossible Dataset, a tool that lets users generate metadata-based synthetic datasets mirroring the structure and coding schemes of the Office for National Statistics Longitudinal Study.
The Longitudinal Impossible Dataset (LIDS) is part of the UKRI ESRC-funded Census Innovation at CeLSIUS project (ES/Z502741/1). Developed at the Centre for Longitudinal Study Information and User Support (CeLSIUS) at University College London (UCL), it is a new synthetic data generation and data discovery tool aimed at supporting prospective and existing users of the Office for National Statistics Longitudinal Study (ONS LS): the largest secure longitudinal dataset in England and Wales.
What is the ONS Longitudinal Study?
The ONS LS follows a 1% sample of the population of England and Wales through each decennial census from 1971 to 2021, linking census data with information from birth, death, and cancer registers. Containing records on over 500,000 people at each point in time, it is representative of the England and Wales population and has been used in a diverse range of research projects across topics including population health, social mobility, education, employment, ethnicity, and migration.
CeLSIUS is the ESRC-funded research support unit for the ONS LS, which it has been continuously supporting since 2001.
Given the richness of the data, access to the ONS LS is necessarily highly controlled and only possible via secure settings in line with the Five Safes Framework. Prospective users must become full accredited researchers, submit a research project application via CeLSIUS, and—if approved—can only access an extract of their requested ONS LS data in a trusted research environment: the Secure Research Service (SRS).
This means that researchers must design projects and identify required variables well before viewing the real data. It also means that researchers are unable to begin developing code before project review and approval have been completed or outside the SRS.
Data discovery on the ONS LS
Prospective users of the ONS LS can browse all publicly available metadata on the study on the CeLSIUS data dictionary. This is an extensive and essential resource documenting all the available tables and variables on the ONS LS as well as any available variable code lists, reference appendices, and other information.
However, with dozens of tables and thousands of variables available, it is often challenging for researchers to determine what variables they need for their research project and to visualise what their requested data extract might look like based on the data dictionary alone.
The Longitudinal Impossible Dataset (LIDS) has been developed with these diverse challenges facing researchers in mind. The central idea is to allow researchers to create bespoke, low-fidelity synthetic datasets—or ‘impossible’ datasets—which they can use to both anticipate the structure of the ONS LS data extracts that they would like to request for their projects and to develop test data analysis scripts prior to accessing these.
Importantly, to eliminate any threat to the security of ONS LS data, LIDS is solely based on publicly available metadata on the CeLSIUS data dictionary. As such, rather than a traditional synthetic dataset based on patterns in real data, it may be more appropriately thought of as a randomised dataset that closely resembles the structure of ONS LS data extracts and the coding of individual variables.
How the LIDS application works
Prospective ONS LS users cannot request access to data on the whole set of available variables as this would pose the risk of disclosing identifying information. Variable selection is therefore an important part of the application process. To reflect this logic, LIDS was developed as an interactive Shiny application rather than a static dataset.
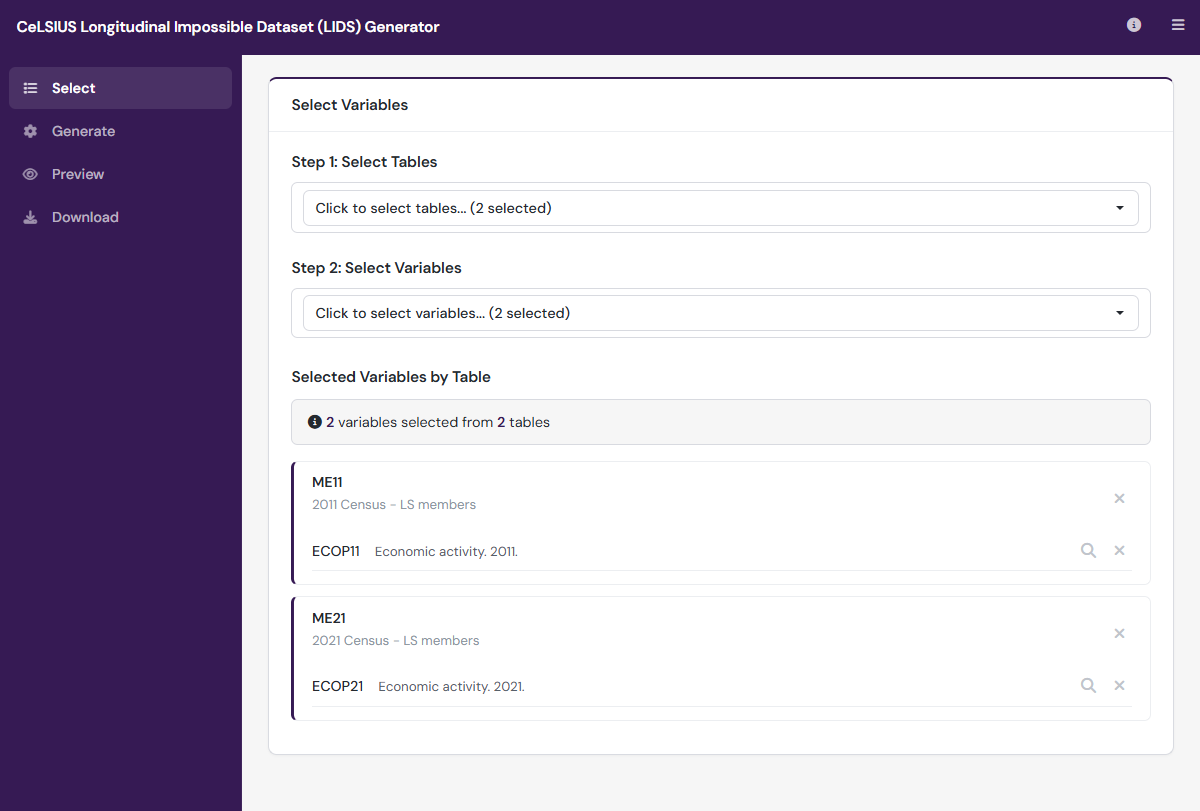
Through the LIDS application front-end, users can:
- Select variables; including options to search and browse.
- Generate an impossible dataset based on their selection; including options to define parameters such as number of observations.
- Preview the impossible dataset; including options to toggle value or label view.
- Download the impossible dataset in various formats.
Figure 1. A snapshot of the LIDS application interface.
ONS LS data extracts follow a relational table structure, meaning that variables are nested in different tables, which for example may represent different census years. This also means that records for the same person in different tables (e.g. census years) can be linked using unique identifiers.
To familiarise users with this structure, LIDS delivers the impossible datasets in precisely this format. Once a user makes their variable selections and clicks on the ‘Generate Dataset’ button, the application produces the dataset by taking random draws from the code list of each selected variable and nesting the resulting observations into their parent tables. It also creates unique identifiers for each observation which are copied across tables.
Figure 2. A conceptual diagram of the LIDS application.
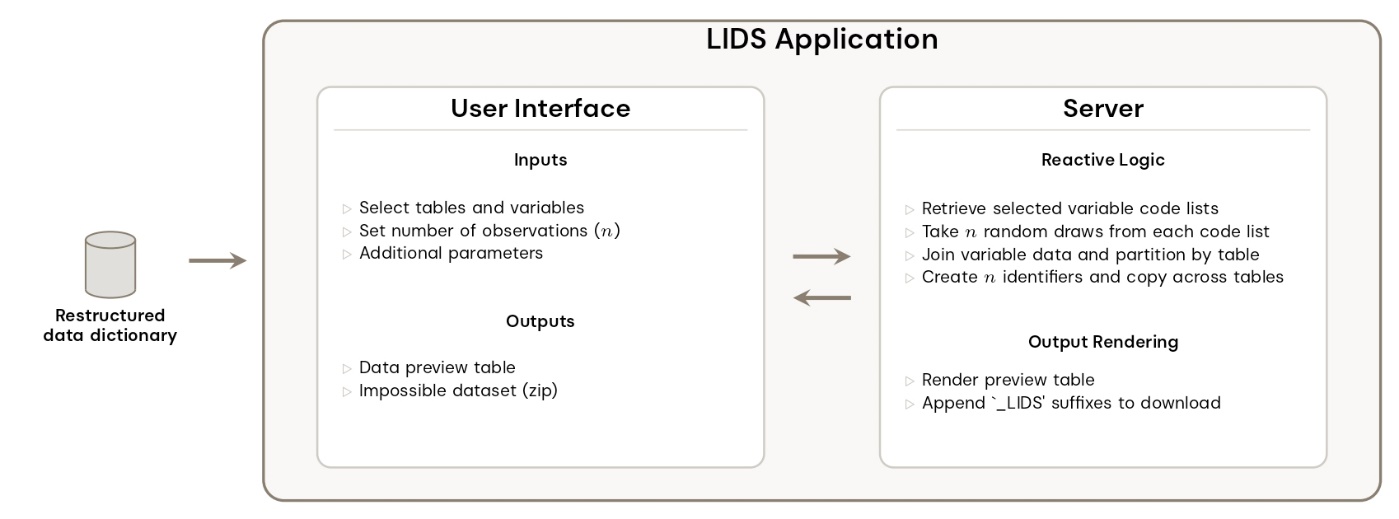
In essence, the impossible datasets created via LIDS have the following features:
- Variable and table naming conventions match those in the ONS LS.
- The structure of the datasets matches that of a real ONS LS data extract, with variables nested within their parent tables.
- Unique person identifiers (CORENO) are automatically generated and applied across tables, mimicking how records are linked in the real data.
- Variable coding schemes are consistent with the public metadata without reproducing any real patterns or relationships.
Use cases for LIDS
We anticipate LIDS will support ONS LS researchers in three main ways:
1. Project planning and data discovery
Prospective users can explore the variables available across different census years and administrative sources, helping them identify which tables and variables are relevant to their research questions before submitting a formal research project application.
2. Understanding data structure
The relational table structure of the ONS LS can be challenging to grasp from documentation alone. By generating and downloading an impossible dataset, researchers can see exactly how linkage of tables via unique identifiers works in ONS LS data extracts.
3. Code development and testing
Researchers can use LIDS to develop and test their data analysis scripts before entering the SRS. While the statistical outputs will be meaningless, the code itself—data cleaning, variable recoding, merging tables, running models—can be tested on impossible data. This can reduce the time researchers need to spend developing code in the secure environment.
It is important to emphasise what LIDS does not do. The datasets it produces are not representative of the ONS LS population or any real-world population. The values assigned to different variables for each observation are independent random draws, meaning there are no meaningful correlations or relationships between variables.
This is precisely why we call them ‘impossible’ datasets. A dataset might contain, for instance, someone with a death record that also has records in censuses following their recorded death, or someone that is recorded as retired at a very young age. These impossibilities exemplify that the synthetic data poses no disclosure risk whatsoever.
Making the most of available metadata
Building LIDS required harvesting and transforming the metadata scattered across the CeLSIUS data dictionary into a format suitable for synthetic data generation. The data dictionary comprises hundreds of individual web pages, each containing variable descriptions, coding information, and links to reference appendices. Our first task was to scrape this information programmatically, ensuring that the input for LIDS was indeed based on public information available to any user with an internet connection.
Not all ONS LS variables have their coding schemes immediately available in the data dictionary. As a project running over several decades, and combining information from multiple censuses and administrative sources, the metadata documentation standards followed for different ONS LS variables can inevitably vary.
For instance, some variables in the data dictionary include information on value-label pairs directly in structured tables. Many others reference external census appendices or classification schemes. A third group embeds coding information only within free-text descriptive notes.We therefore developed a classification system to determine the most appropriate extraction method for each variable.
A key insight was recognising that many variables share coding schemes across census years and tables. By building a graph of relationships between variables—through shared classifications, explicit cross-references in the documentation, and similar descriptions—we could identify clusters of comparable variables. This allowed us to propagate code lists from variables where they were available to related variables where they were not, substantially increasing overall coverage.
Figure 3. Determining variable code list extraction methods.
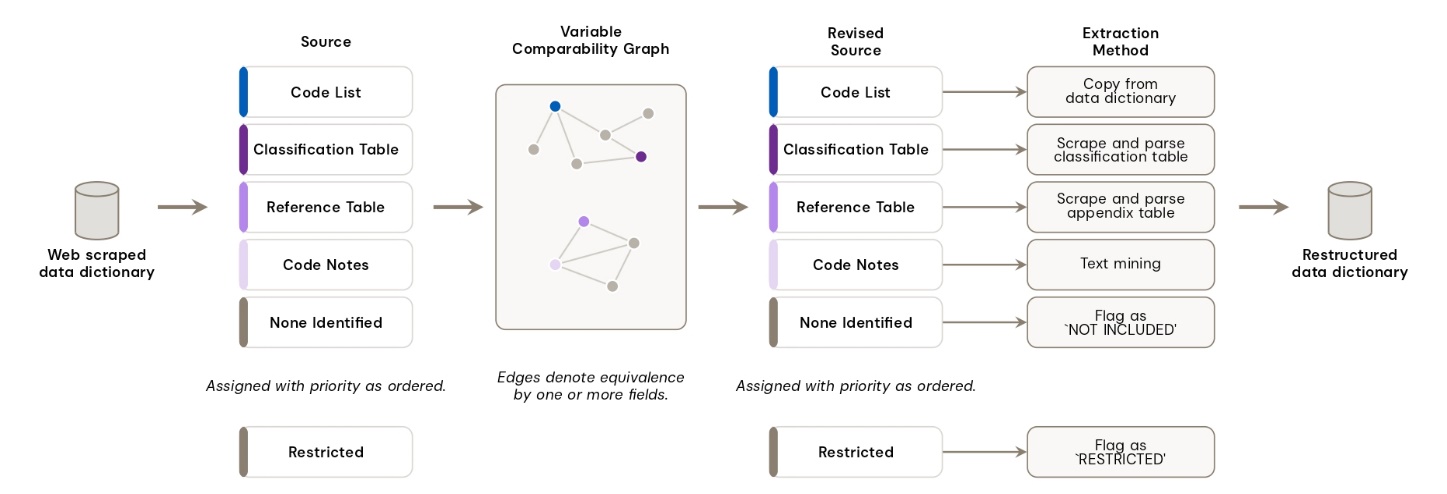
The result of this was effectively a reconstructed data dictionary including structured value and label information, or code lists, for a greater number of variables. LIDS was then developed as an R Shiny application drawing on these very code lists to create user-requested impossible datasets.
Accessing LIDS
LIDS is freely available to all users. Details on how to access it can be found on the CeLSIUS website. Users can either run the application locally by installing an R package or directly visit the online hosted instance. No registration or accreditation is required—the tool is designed to be as accessible as possible to anyone interested in exploring the ONS LS. We encourage prospective ONS LS users to experiment with LIDS as part of their project planning process and welcome feedback on how the tool might be further developed to support the research community.
About the author
Dr Andreas Mastrosavvas is a Senior Research Fellow in Census Innovation at the UCL Research Department of Epidemiology and Public Health.
At CeLSIUS, he leads on the development of the Longitudinal Impossible Dataset, new census support services, and research projects using secure census microdata and flow data.
To find out more about Andreas’ research, check out his professional profile.
Comment or question about this blog post?
Please email us!