
Oliver Duke-Williams, @oliver_dw, Senior Lecturer in Digital Information Studies in the Department of Information Studies at UCL and Co-Investigator at the UK Data Service, updates us on proposed new uses for administrative data in place of censuses in the area of estimates of journeys to work.
In November, the Office for National Statistics (ONS)’s Administrative Data Census Project released some updates on their progress including estimates of ethnicity and journey to work.
There is considerable interest both within ONS and the other UK statistical agencies, and in the wider community, including the academic Administrative Data Research Network (ADRN) in the use of administrative data to wholly or partially replace the decennial census. The logic for this approach is clear; taking a census is an expensive operation and the data captured become increasingly out of date as time moves on.
Much data is gathered by a variety of national and local government departments and agencies as part of their everyday operation, and some of these data cover similar demographic themes to those data collected by a census. If it were possible to extract from these administrative sources equivalent data to those data collected by censuses, then it may be possible to save the expense of conducting a census and have continually updated data.
Of course, the fact that the UK is not already using administrative data in place of censuses indicates it’s not quite as easy as that; there are a variety of problems to be overcome with administrative data including questions of completeness, accuracy, legal feasibility and definitional compatibility.
One of the areas where there are difficulties in replicating census outputs is in data about journeys to work, which is why ONS’ report is interesting. The census asks a number of questions about employment including place of work and the way in which people travel to work. Responses enable the construction of a detailed matrix of flows from residences to workplaces, disaggregated by mode of travel and other characteristics. There are no obvious administrative replacements. Taxation data might permit a connection to be made between an individual’s home and their place of work, although it may well be the case that the tax record identifies the location of a business headquarters or payroll department, rather than the location in which the individual actually works. Even if taxation data did identify workplace locations reliably (and could do so for the self-employed as well), there would still be no linkage with mode of travel to work.
A possible way round this problem is to look at big data sources as well as administrative sources, with one example being movement as indicated by changes in mobile phone location data, which is exactly what ONS have studied.
The findings are interesting and deserve exploration from the point of view of those interested in the census journey to work outputs. The overall findings of the report are that (for a small set of local authority level test areas) there is a good correlation between longer distance flows reported in census results and those determined from analysis of phone data. The authors of the report are cautious in their interpretation and acknowledge a number of problems with the method.
So, what are the concerns?
Perhaps the most obvious question that we can ask is whether enough people carry phones with them for data of this sort to be considered a viable alternative? Ofcom data indicate that 94% of adults own or use a mobile phone, which would suggest that the answer to that question is ‘yes’. However, it is unclear whether all of these adults carry a phone at all times (or at least, during their commute). Assuming that they do, is the phone location (that is, the local cell tower to which they are connected) reliable? This might be more problematic: phone coverage is variable across the country, thus the ability to estimate people’s home and workplace locations is also variable.
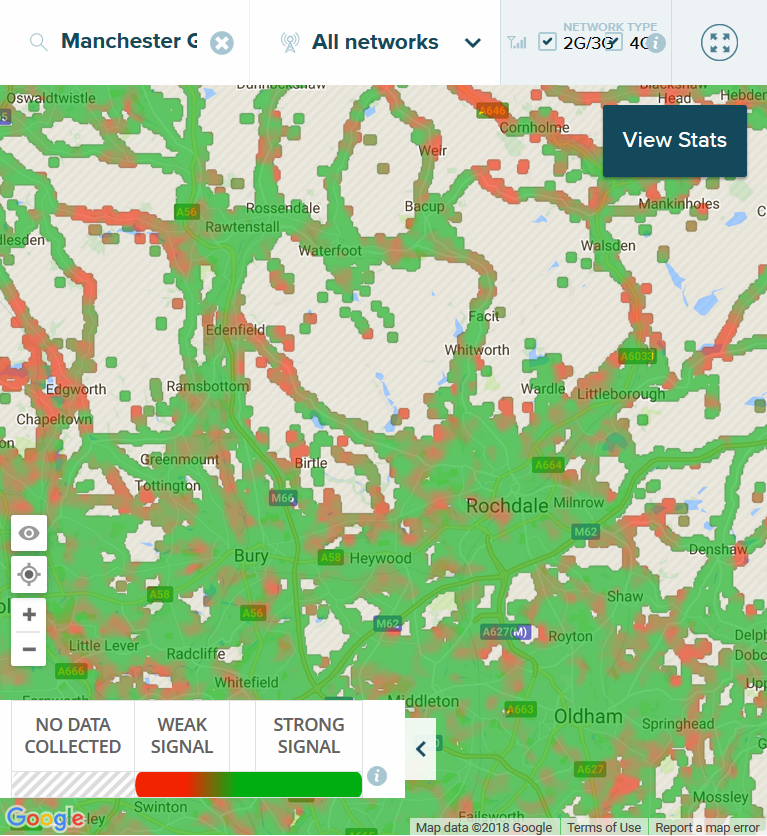
Open signal: 3G and 4G mobile phone coverage map
The report notes that experiments were conducted in conjunction with mobile phone providers and that the methodology can’t be fully disclosed. This is a meta-concern for those of us interested in transparency of data sources as it limits the amount that can be understood about the method. Home and workplace locations are seemingly determined by phone locations at various times of the day, with the same phone having to be in the workplace for a particular length of time, with repeated observations over a monitoring period. Previous research has suggested that (for normative commuters) both home and workplace can be identified with quite a high degree of accuracy.
The description of the methodology states that subscribers known to be under 18 were excluded from the analysis, leading to a set of related concerns. The data are anonymised before processing; necessary from the point of view of the mobile provider, but problematic for any attempt to generate census-type data. There is no way to link a given phone record to an individual, and thus to individual and household level characteristics. The ability to link is central to the richness of census outputs. Without individual level data it is hard to filter out data that are not required. In the case of journey to work data, that would include persons aged under 16. Whilst this information might be known for some people, it will not be robust: it is not uncommon for young people to have a phone for which the contract is in a parent’s name.
Over-collection of data may be another problem perhaps; one 2016 report states (without giving a source) that 14m people in the UK carry two mobile phones. This is likely to be a non-random sample of people, and would potentially distort results. Even if there were clear records of phone ownership, it seems legally and practically unfeasible to link phone records to any other record level data and data modelling would be required.
In census data the home location, workplace location and method of travel to work are all explicitly recorded, as are characteristics of the job and of the workplace. With phone data, home location and workplace location are determined from the data, and any other characteristics have to be estimated. At best the phone workplace location might be estimated to a sufficient level of accuracy that a reasonable assumption can be made about the specific employer, but details of the job itself would remain unknown.
The ONS methodology does not expand on the manner in which mode of transport was assigned and so it is assumed to be modelled on existing data about journeys between the home-workplace location pair. If this assumption is correct, it is a sign of weakness in the methodology; we’d be modelling modal splits based on modal splits from older censuses, which would be increasingly out of date. That’s not a particular criticism of the journey-to-work data however, it is an inherent problem in administrative data and big data solutions where individual level identifiers (which would permit data to be linked together) are not known, or cannot be used.
In principle, phone data could indicate not only ‘resting’ locations but something about the journey between those locations as well – the time taken and some details of the route (based on a series of cell-tower connections). These elements could perhaps allow a much more sophisticated estimate to be made about the transport mode, although the data themselves would be significantly more complex to process. However, some types of journey to work flows cannot be captured well by either the basic methodology or by more sophisticated tracking – including people working from home and people with no fixed workplace.
Another problem is that for local level flows (within the same local authority) it would be almost impossible to distinguish commuters and other phone users. School students would present a particular problem in this regard, as they have temporal structures (when they are at home, and when they are at school) that are quite similar to commuters. Can we just ignore data for which the daytime location is a school? No – because then we’d exclude school employees as well. Again, we are faced with the problem that without individual level characteristics, these data pose many problems.
Can we just ignore local level flows? This would be a mistake: intra-area flows are hugely important. They’re short distance thus exactly the ones one might hope to convert from motorised to active commute – so it would be necessary to understand the modal split accurately for these people – but they also account for a large number of persons. Data from 2011 show that 52% of journeys to work in England and Wales occur within the same local authority.
Despite these concerns it is useful that ONS have carried out these tests. The data look promising for certain types of commuters and it is assumed that the methodology will improve. The traditional census form is also not ideal for capturing information on journeys to work. Space is constrained on any paper-based form (and overall completion time is an important constraint for online forms) so only a single question is asked about the journey to work (coupled with questions about the location of the workplace) further questions would be required to identify for example, additional transport modes used or about commute times and intermediate destinations.
Sample question from the 2001 Austrian census
There are many problems in viewing the use of mobile phone data as a compete replacement for the journey to work data collected by a census. There are issues with under and over-collection of data, and of determining the mode of transport, but even if these aspects could be addressed, there remains the fundamental issue that these data cannot be linked directly to other individual level characteristics (whether gathered from administrative data sources or from a minimal census). They cannot be, unless the user of every phone was correctly known and phone companies were prepared to share that information. However, tracking the movement of phones offers the ability to garner more information than a simple form; in a similar manner to the way in which Transport for London have studied alternative routes from A to B through the tube network it might be possible to look not just at modes of transport, but routes as well.

TfL Review of the WiFi pilot
That information would be useful for understanding the social impacts of the journey to work; it is not just the home location and the workplace location affected by the environment impact of cars, but areas in between as well. At present we can make assumptions about those areas, but in principle we could understand more.
Recent research has also highlighted concerns about the possible risks posed by mobile phone data in relation to data gathered via traditional census means; if the census outputs are published at a high level of spatial detail. A mobile phone data set with person identifiers might act as a key to census data, leading to attribute disclosure. Whilst it is reasonably easy to protect census data (at the cost of user access) this example indicates the tensions between administrative census collection and traditional forms (whether they be collected on paper or online). The existence – or potential existence – of a census-like data set (in the form of administrative data and big data) places new constraints on the ways in which data can be made available from traditional censuses, at odds with increasing expectations of open data. Whilst these constraints can be addressed with both open data and (more detailed) restricted-access versions, there must be a risk that it becomes easier to simply not release the more detailed data.