 Olajuwon Yakub discusses how behind-the-scenes engineering at the UK Data Service ensures access to reliable, high-quality data for researchers driving real-world impact.
Olajuwon Yakub discusses how behind-the-scenes engineering at the UK Data Service ensures access to reliable, high-quality data for researchers driving real-world impact.
Every Monday morning, before I begin my tasks for the day, I carry out routine checks on our platforms to ensure that all services are running smoothly and that users can access data without disruption.
One of the platforms I always review is our Data Impact blog, a space dedicated to telling the stories of how researchers, charities, and public bodies use UK Data Service data to create meaningful, real-world impact.
During one of these checks, I came across a blog post by the Royal British Legion reflecting on the inclusion of a veteran status question in the 2021/22 Census. What caught my attention was not just the story itself, but what it represented: the power of high-quality, well-designed data to fundamentally change how communities are understood and supported.
For years, the Armed Forces community had been largely invisible in national datasets. The introduction of a single, carefully considered census question closed a long-standing data gap and unlocked reliable insight into who veterans are, where they live, and the challenges they face.
The introduction of this new census question has played a pivotal role in shaping policy, influencing local authorities, improving access to financial support, and informing targeted health and wellbeing services.
Reading this as someone who works behind the scenes to keep data platforms reliable and accessible was a powerful reminder of why data quality matters so much. Accurate, inclusive data enables evidence-based decisions, gives credibility to advocacy, and turns abstract statistics into tangible outcomes for real people.
As a Data and Platform Engineer within the UK Data Service, my responsibility, alongside my colleagues, is to ensure that large national and international datasets, including census, population, demographic, and economic data, move from raw state to trusted, analysis-ready data in a controlled, predictable, and auditable manner.
The impact described above, and several others like it are only possible because the datasets we provide are engineered with quality, governance, and reliability at their core. Without the processes that support this, these stories, and the impact they drive, simply would not be possible.
The challenges and solutions that shape user experience
In order for researchers to drive this impact, they need to access data via the UK Data Service in a reliable and seamless way that supports their work from start to finish.
This means that we need to think about any potential obstacles and implement solutions before they are a problem.
Repeated manual processes can introduce errors and slow the pipeline
One of the challenges we face in the publication pipeline is the number of processes that must be carried out repeatedly when preparing datasets for publication. Tasks such as loading data into the platform, preparing files for transformation, and uploading them into the transformation engine often must be executed multiple times across a single dataset.
In some cases, I may find myself performing the same sequence of steps dozens or even hundreds of times, especially when working with large datasets or multiple structures that need to be processed individually.
This level of repetition introduces several risks. The more manual steps involved, the higher the likelihood that small errors may occur, whether through selecting the wrong file, mis-configuring parameters, or missing a step in the process. Even minor inconsistencies at this stage can affect the integrity of the final dataset.
Beyond the risk to data quality, repeated manual processes also slow down the overall pipeline. When progress depends on repeated manual actions, it increases the time it takes for data to move from its raw state to a form that researchers and analysts can use. Ultimately, this affects how quickly data becomes available to those who depend on it.
How did we overcome this challenge?
To reduce the risks associated with repeated manual processes, we introduced automation into several parts of the data publication pipeline. Previously, many tasks such as loading datasets into platforms, triggering transformation processes, and preparing files for ingestion had to be executed manually and repeatedly.
By implementing automated scripts, these steps can now run consistently with minimal manual interaction. Automation ensures that the same sequence of actions is performed each time, reducing the likelihood of human error and improving the consistency of the data processing workflow.
Automation also helped coordinate activities across different systems. Instead of manually triggering processes in multiple environments, automated workflows now manage these transitions and ensure that each stage of the pipeline executes in the correct order. This has significantly improved both the reliability of the pipeline and the speed at which datasets become available to end users.
Cross-system workflows can threaten data quality and make troubleshooting difficult
Another challenge we encounter comes from the fact that the dataset publication process spans several different systems and services. Throughout the pipeline, we often must move between platforms to carry out different stages of the workflow, from extraction and transformation to validation and final publication.
Each of these systems serves a purpose within the broader architecture, but moving across multiple environments introduces additional complexity. It means that the workflow is not always contained within a single, streamlined process. Instead, it requires coordination across several tools and interfaces.
From a data quality perspective, this can make it harder to ensure complete consistency across the pipeline. Differences in system behaviour, configurations, or processing steps can sometimes lead to variations in outputs if not carefully managed.
It also makes monitoring and troubleshooting more difficult. When something goes wrong, identifying exactly where the issue occurred across several systems can take time, which in turn delays the availability of the dataset for users.
How did we overcome this challenge?
To address the complexity of working across multiple systems, we introduced orchestration into the pipeline. Orchestration is the automated scheduling, coordination, and management of data tasks to ensure they run in the correct sequence, with proper dependencies and error handling.
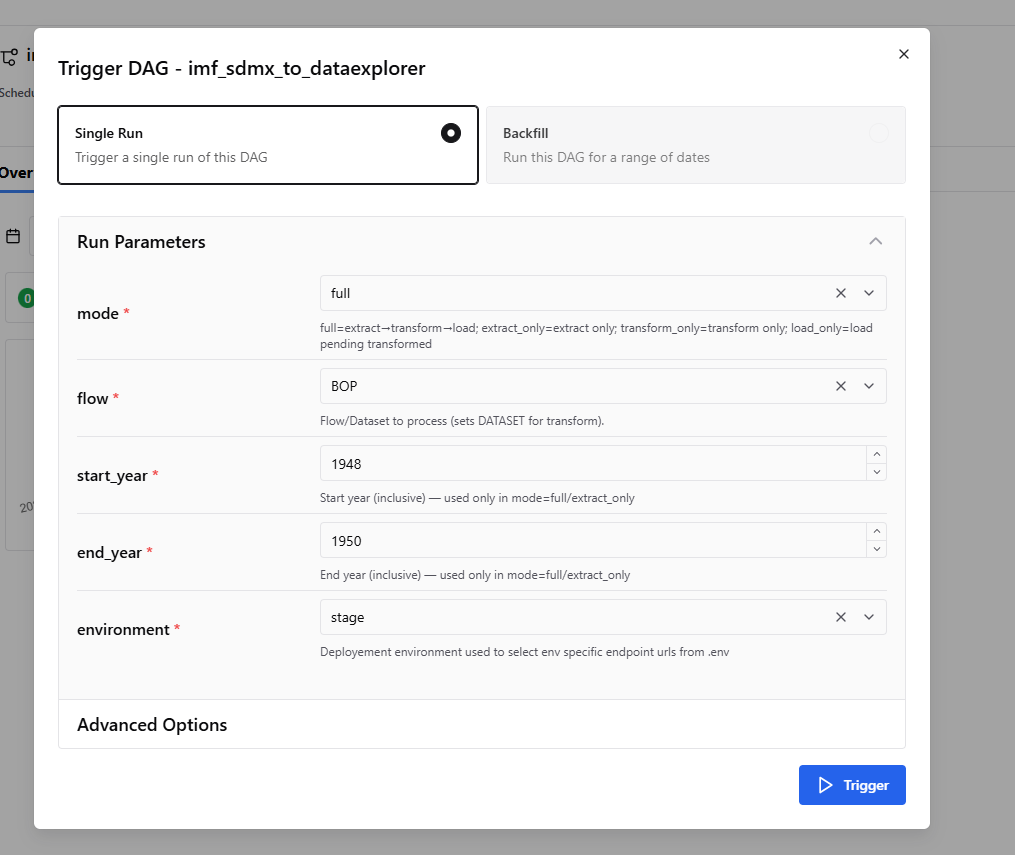
With orchestration in place, the workflow is now coordinated through a structured process that controls how and when each stage runs through runtime selections, which as you can see in Figure 1 below.
The orchestrator ensures that tasks are executed in the correct order and only begin once their dependencies have been completed successfully.
In addition, parts of the pipeline that were previously executed on local machines were migrated into a shared cloud environment. Moving these processes to the cloud centralised the workflow, improved accessibility for the team, and made it easier to monitor and manage the pipeline.
Together, orchestration and cloud implementation have improved the transparency, reliability, and maintainability of the system.
Figure 1: orchestration platform at runtime showing the options available for selection before running the pipeline.
Handling large datasets can introduce a unique set of risks
Working with large-scale datasets introduces another set of challenges, particularly around scalability and reliability.
Many of the datasets we process, including census and population data, are substantial in size and continue to grow over time. As the data grows, the computational resources required to process it also increase.
Without careful management, processing large volumes of data often push systems resources beyond their limits. For example, I have encountered situations where memory usage increases significantly during processing, eventually leading to out-of-memory errors that cause jobs to terminate unexpectedly.
In addition to resource constraints, reliability is also a concern. Because the pipeline often interacts with network-based services, temporary issues such as network interruptions or service timeouts can cause processes to fail midway through execution. When this happens, the pipeline typically needs to be rerun from the beginning or from the last available checkpoint.
Rerunning processes introduces its own risks. If the pipeline is not designed to be fully idempotent—in other words, it can be run repeatedly without change—restarting a job can led to duplicated records or repeated data inserts.
In certain scenarios, this can unintentionally inflate values, create duplicate observations, or introduce inconsistencies in the dataset being processed.
These types of issues can compromise both the accuracy of the data and the trustworthiness of the final outputs.
Another challenge we encounter with large datasets is maintaining the consistency of their structure as they move through the pipeline. This is because large national datasets can evolve over time, with new variables introduced, codes updated, or structures adjusted between releases.
Without proper validation checks, these changes can introduce inconsistencies that affect how datasets are processed or integrated into downstream systems. Ensuring that datasets maintain a consistent and expected structure is therefore essential for preserving data quality and preventing processing failures.
Beyond the datasets themselves, metadata plays an important role in how data is understood and used.
Researchers and analysts rely on metadata to interpret variables, understand dataset structures, and correctly apply the data in their work. If metadata is incomplete or inconsistent, it can make datasets difficult to interpret, even when the underlying data is correct.
How did we overcome this challenge?
To improve the system’s ability to process large datasets, we introduced techniques designed to improve scalability and resource efficiency. These include stream-based processing, multipart uploads, and lazy loading.
Stream-based processing allows datasets to be processed incrementally rather than loading entire datasets into memory at once. This significantly helps us to reduces memory consumption and helps prevent failures such as out-of-memory errors when we are working with large data volumes.
Multipart uploads also improve reliability when transferring large files to remote/cloud storage or services. Instead of uploading a large file as a single operation, files are divided into smaller segments that can be uploaded independently and reassembled on the receiving end. This allows uploads to recover more easily from interruptions.
Lazy loading further improves efficiency by ensuring that data is only loaded into memory when it is required.
Together, these techniques allow our pipeline to process large datasets more efficiently and reliably as data volumes continue to grow.
To ensure datasets maintain structural consistency throughout the pipeline, we implemented a layered data lake architecture. This approach separates datasets into different stages of processing, such as raw, load, and transformed layers.
Storing data in layers allows the original datasets to remain preserved while transformations are applied to downstream versions of the data. This structure improves traceability and makes it easier to understand how datasets evolve throughout the pipeline.
We also applied the principle of separation of concerns within the pipeline. This means that instead of building monolithic scripts that handle multiple responsibilities, the workflow was divided into smaller components responsible for specific tasks such as extraction, transformation, validation, and publishing.
This modular design makes the pipeline easier to maintain, test, and debug. It also helps ensure that structural validation and transformation logic are applied consistently across datasets, improving overall data quality.
To address potential failures due to temporary network interruptions, service timeouts, or other transient issues, we introduced several reliability mechanisms within the system.
One of the most important improvements was implementing retry logic with exponential backoff. When an operation fails due to a temporary issue, this means the system automatically retries the task after a delay, allowing many transient errors to resolve without manual intervention.
In conclusion
In conclusion, while much of the work behind data platforms happens quietly in the background, it plays a critical role in ensuring that datasets are reliable, accessible, and ready for meaningful use.
The improvements we implemented across the pipeline from automation and orchestration to scalable processing and reliability mechanisms, were designed to ensure that data moves through the system in a controlled, predictable, and trustworthy way.
These engineering decisions ultimately support something much larger than the pipeline itself.
They help ensure that researchers, policymakers, and organisations can access high-quality data when they need it.
As illustrated by the Royal British Legion’s use of census data, when reliable data is made available, it can reveal previously unseen realities, inform better decisions, and drive meaningful change for communities.
Meet the author
Olajuwon Yakub is a Data and Platform Engineer working in the Census Aggregate and International Macrodata team for the UK Data Service, which is based in Jisc.
Comment or question about this blog post?
Please email us!