
Paul Chau, a Data Architect at the UK Data Service, explores how the Data Explorer platform enhances data interoperability through in-built transfer services and SDMX.
If you are a follower of this blog or a user of our international data, you may know that we launched our new Data Explorer last year – a powerful data platform developed by SIS-CC. While you may have already experienced the functionality of Data Explorer and got hold of your desired piece of subsetted data, there’s more to the full potential of this new platform.
What is behind Data Explorer?
Data Explorer reads data based on an ISO standard called Statistical Data and Metadata eXchange (SDMX, ISO 17369). The standard aims to provide understandable structures and a standardised approach to data, opening up opportunities to automate data exchanges.
SDMX is designed to enhance data semantics, provide a backbone and a common language, and allow improved data governance using a set of defined structures to map with statistical concepts and referential metadata. A standardised, well-defined structural language enables experts and platform holders to work with the same workflows, furthering cross-domain communications or data harmonisation.
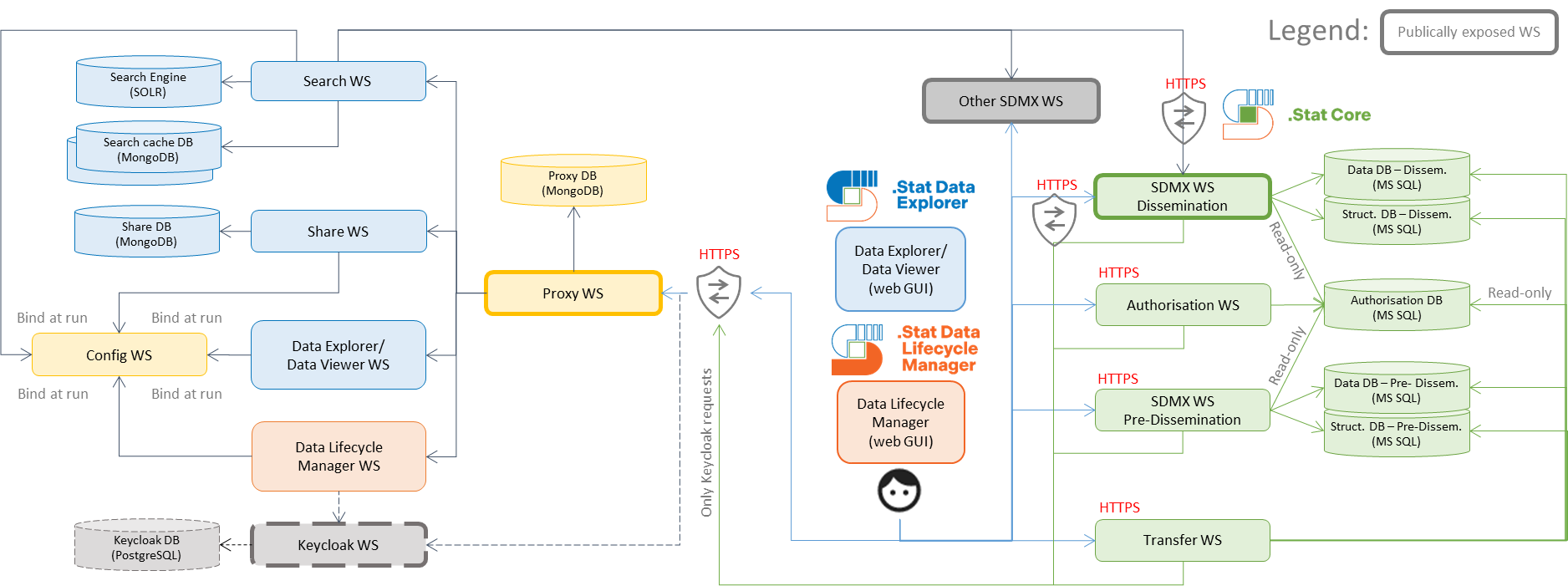
Although you are viewing and extracting data from Data Explorer, behind it is actually a full family of web services – “DotStat Suite”. As shown in the figure above, when you are searching for a dataset on Data Explorer, the request is actually relaying inside different web services in the family for extracting, organising and displaying data for you (indicated by blue lines pointing to green boxes).
It is like a team of cooks in the kitchen handling your order in the restaurant. And to communicate within that team, you will need one single common language. In “DotStat Suite”, the language is called SDMX.
Therefore, with the help of the whole architecture, any user of Data Explorer can fully enjoy the benefits of SDMX. More discussion on SDMX can be found in this blog post, which further explains why SDMX matters.
Data interoperability
Data interoperability refers to approaches that would enable different systems to communicate with each other about their data seamlessly, allowing data exchange, unified data interpretations, and cross-platform usage of data.
Imagine Organisation A provides a set of “Country of birth” demographic data in England and Organisation B is researching the health conditions of migrants, and thus needs “Country of birth” data. To make use of the data, Organisation B needs to know:
- the open format (i.e. file format being XML, CSV, JSON, etc.) for the “Country of birth” data that Organisation A is providing.
- a clear definition of “Country of birth” and the corresponding vocabularies underneath it.
- any corresponding frameworks and protocols for using the data.
These requirements are a few of the challenges to data interoperability. Successful solutions to them can extend the idea further into cross-disciplinary research and open more opportunities for collaboration.
As you can see from the above example, data interoperability is an important concept that describes data integration and exchange across different information systems and applications. This means the data are not just stuck with their original purpose in a single system by the data provider but can also possibly be used by other applications and parties for extended purposes.
Data interoperability also allows partial adaption of the data definition from other parties. In the above scenario, platforms with data interoperability would allow Organisation B to make use of Organisation A variables of “Country” even if the “Country of birth” data cannot be fully adopted. Organisation B only needs to arrange the use of the “Country” variable in their own definition and investigate time in the usage instead of the basic variables on their statistics.
This shows that, in modern day environments, the capability of data interoperability is crucial in reducing time for basic structural definitions and getting businesses focused on their corresponding innovations.
How does Data Explorer / DotStat Suite achieve this?
Under the DotStat Core, DotStat Suite allows the system to be set up with a simple connection to external data sources outside the organisation. This is achieved by two designs of DotStat Suite:
1. In-built Transfer Service
Data in DotStat Suite are stored in databases. To retrieve the data, a middleware called Transfer Service serves as a connecting node between the front-end and the database. Therefore, by providing the correct pathway, even external services can be connected to a local DotStat Suite through Transfer Service to exchange and handle all the protocols for using the data.
As an example, we are now able to directly connect the Transfer Service underneath our UKDS Data Explorer with OECD Data Explorer, allowing us to view and examine useful structure and data from the OECD on our own Data Lifecycle Manger.
2. Fully SDMX-based database setup
DotStat Suite is designed based on SDMX, allowing it to communicate not only to DotStat Suite but also to other SDMX-based applications like FMR (Fusion Metadata Registry) Workbench. The definition of SDMX also provides the common ground for further expansion and semantic handling for data and referential metadata.
With these designs, data are easily exchangeable and shared across sources and applications, given that they all communicate using the same language: SDMX. The readability and precision of SDMX allows data to be easily handled in different environments and interpreted without misunderstanding. This is a very important requirement for data interoperability and further broadens the horizon for future possibilities in data usage.
In the AI era…
The application of AI in a practical environment has finally come to reality. However, this is all data-driven, and it is thus obvious that the quality of data is of utmost importance as a driver of such a revolution.
Both machine learning and AI models require data to enhance their abilities. When more quality data are made available, more useful tools can be built. Increasing data interoperability and making the data more FAIR (Findable, Accessible, Interoperable, and Reusable) are key parts to this. DotStat Suite unlocks the potential of data exchange and allows a more structured, clear and usable approach for cross-organisation data research.
What’s next, particularly for the UK Data Service?
For our UKDS Data Explorer, we are now transforming the latest UK Census data into an SDMX-compatible format. After that, older UK Census data will be provided. We are also working with collaborating internationally to continuously introduce the latest international data into the platform.
We hope that by bringing more data into the SDMX format, users can enjoy the benefits of data interoperability in supporting their innovative ideas.
About the author
Paul Chau is the Data Architect of the UK Data Service, based at Jisc, and is mainly responsible for Census Aggregate Data and International macrodata.
Throughout his career, he has been dedicated to supporting digital transformation, especially in the education and public sectors. Migrated from Hong Kong, Paul has been with the team since 2021 and has been working on modernising data platforms, and is a key player in setting up CKAN and Data Explorer for the UK Data Service.
Follow Paul on LinkedIn.
Comment or question about this blog post?
Please email us!