 Finn Dymond-Green examines the need for persistent identifiers for digital content, as the UK Data Service welcomes the UK Government’s consultation on using the DOI standard.
Finn Dymond-Green examines the need for persistent identifiers for digital content, as the UK Data Service welcomes the UK Government’s consultation on using the DOI standard.
2020 is a year when many of us live our lives even more online than before. While it may be a pandemic which has kept many of us anchored to our phones, tablets and laptops, it’s really only the culmination of a trend which has been developing since the invention of the internet.
As we spend more time online, we produce ever increasing amounts of digital content, some of it ephemeral (such as Twitter’s announcement of its new Fleets – tweets which disappear after 24 hours), some of it longer-lasting but of importance mainly to ourselves and those close to us (according to Google, 28 billion new photos and videos are uploaded to its soon-to-be restricted Google Photos service), some of it takes the form of official documentation and regulation. Equally while some of the mountains of digital content available are academic papers and other publications, much of it is collected data.
It has increasingly become difficult to guarantee finding exactly the digital object we want (think of it like an extreme example of ‘it’s on the tip of my tongue’), both because of the ever increasing amount of digital content to organise and catalogue, but also because of inbuilt constraints of the internet.
Take the example of an organisation which completely redesigns its website.
In the process, some older content (which may still be of relevance to users) is lost in the transition, while other content is placed in new areas of the website.
For users of the previous version of the site who have bookmarked a page with this content, have found it through a search engine which hasn’t yet updated its index for the site, or perhaps just have good muscle memory to help them navigate the steps they need to take to get there, suddenly the content is no longer easily available.
No doubt every reader of this post has, at some time or other encountered an ‘Error 404’ page or perhaps one which gives a slight more user-friendly message such as ‘Oops. We can’t find what you’re looking for.’
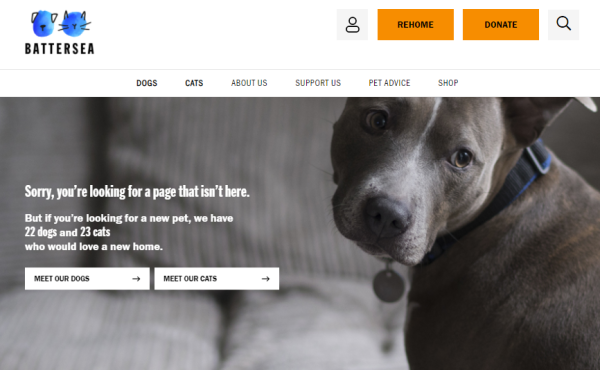
Image: Error 404 page for Battersea Dogs and Cats Home
“But I really need to find that page!”
Of course, just because a website team has decided to move or delete some digital content, that doesn’t mean the content isn’t still sometimes important or relevant to users, and this is where the concept of digital preservation come into play.
Digital preservation has much in common with the principles and processes that museums, art galleries, special collections libraries, archives and the like have developed over time.
These principles include knowing what the item is, what its provenance is (where and when it came from), other contextual information (such as the person behind created objects) and, indeed, where to locate items.
Given the expanding and global nature of digital content, these principles also need to be standardised. Just as books have ISBNs to identify their author, title, edition and variation, persistent identifiers are used as a long-term reference to a digital resource.
Persistent identifiers typically comprise two parts:
- a unique identifier for the resource (to record and guarantee its provenance)
- a service which will link the identifier with the location of the resource, no matter how often its location on the internet changes
Different schemes for persistent identifiers have been created, such as Digital Object Identifiers (DOIs), Handles, Archival Resource Key (ARK), Persistent Uniform Resource Locator (PURL) and Universal Resource Name (URN).
A key concept behind each of these schemes is that they are standards-based. Anyone using these schemes, whether as a digital preservation expert or as someone trying to find a digital resource should always expect the scheme to work in the same way.
The UK Data Service and DOIs
The UK Data Service is at the forefront of using persistent identifiers to identify datasets, both in terms of their content and variations (e.g. new editions) and where they are stored.
Persistent identifiers give users confidence that, even if the underlying web address for the dataset changes in the future, the dataset will always be locatable.
The UK Data Service uses persistent identifiers know as Digital Object Identifiers or DOIs. All catalogue pages for individual datasets include a link to the DOI, as well as a handy ‘copy and paste’ tool (see the purple ellipse in the image).
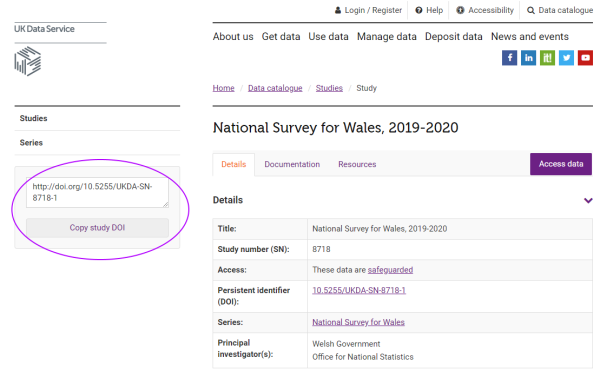
Image: UK Data Service catalogue page for National Survey for Wales, with DOI tool highlighted.
Using the study’s DOI will always bring the user back to this edition of this dataset, even if its location on the internet should change in the future.
The DOI, however, is only part of the story of how researchers acknowledge that they have used particular data.
Just as they acknowledge their use of a book, journal article or other publication with a citation, researchers cite the data they use. The UK Data Service also provides a handy citation tool on each catalogue page, with different formats and download options available:

Image: Excerpt from catalogue page for National Survey for Wales, showing citation tool.
The UK Data Service is a leader at encouraging the citation of data, including our #CiteTheData campaign.
An advantage for the UK Data Service of researchers citing their use of data is that we can understand which data are used, how much and in which areas of research.
Importantly, when data citations are used, we are able to track where research using the data has had impact on communities, policymakers and so on. Citing data in the collection also helps us highlight the importance of the Service and ensure we continue to be funded to make access to high quality social, economic and population data widely and easily available.
The UK Government and DOIs
The UK Government has recently opened a consultation on using DOIs on data and documents it publishes.

The Government’s call out recognises the expertise of the UK Data Service in moving things forward in this area, as well as noting the problems involved with their current system of not using persistent identifiers.
The consultation looks for input on questions of costs (both for setting up and maintaining a system, but also of any potential publication delays), how DOIs could be structured to deal with the complex organisational structure of government, whether DOIs meet government criteria for open standards and whether their introduction could cause any confusion or other unintended consequences for users, especially those who may not be familiar with their use.
The UK Data Service welcomes the consultation and will be making its own submission. We encourage other interested parties to also contribute before the end of December when the consultation closes.
About the author
Finn Dymond-Green is the UK Data Service Director for Impact.