Impact case studies will form an important part of submissions to the Research Excellence Framework (REF) in March 2021, just as they did for 2014. With just over three months to submission, find out why citing data in impact case studies is a great way of enhancing their ‘FAIR-ness’ and supporting the persistence of the components of impact case studies, REF to REF as its digital footprint increases in scope.
The UK Data Service uses digital object identifiers (DOIs) for each of the data collections we make available for citation in research and teaching. We track the citation of the data in our collection through DataCite via our prefixes provided by the British Library. DataCite is a service that enables people to search for registered datasets, via the metadata associated with the datasets.

Image: DataCite logo and web page
Data citation is central to our understanding of the use of the data, within and beyond academia and a key element in how we understand, measure and promote its impact.
Back in 2017 we wanted to find out how much data from the UK Data Service data collection were used in impact case studies in the 2014 Research Excellence Framework, which data and the case studies they were used in, but we noted that of the impact case studies using data in the UK Data Service collection, all had included data collections by name, rather than digital object identifier.
So we tasked ourselves with mining some data from Research England’s excellent application programming interface (API) of impact case studies submitted to the 2014 Research Excellence Framework.
Using the API, we started with a list of what we knew were frequently used data in the collection and ran a script to run through each Unit of Assessment to return a list of those that were referenced or mentioned in any REF 2014 Impact Case Study.
The sixty or so impact case studies we found from our initial data-mining, the scripts for which used just a few of the data collections in the UK Data Service collection to support their development (or the underpinning research) were found in units of assessment ranging from Sociology to Economics and Econometrics, Psychology, Psychiatry and Neuroscience, and Modern Languages and Linguistics.
They covered a range of impactful research from higher education institutions across the UK including:
- Better measures of fuel poverty which used data from the English House Condition Survey (doi:10.5255/UKDA-SN-6106-2) and the British Household Panel Survey (doi:10.5255/UKDA-SN-7453-9) to look at the extent to which being in fuel poverty persisted over time, and the effects of turnover in the housing stock
- Using analysis of cohort studies to inform social-mobility policy which analysed all available UK cohort data to explore the sources of intergenerational social mobility
- Improved screening for dyslexia worldwide to anonymously identify dyslexia in over 8,800 mid-thirties year-olds from the 1970 British Cohort study (doi:10.5255/UKDA-SN-6557-4).
Matthew Woollard, Director of the UK Data Service says:
“The UK Data Service is at the forefront of using persistent identifiers to identify datasets, both in terms of their content and variations (e.g. new editions) and where they are stored. ‘Persistence’ means that even if the underlying web address for the dataset changes, the DOI won’t, so it always links to the data that were used for that piece of research. A DOI is automatically assigned to any data collection deposited into the UK Data Service. DOIs are part of the international standard, ISO 26324.”
Citing the data is as easy, and uses the same techniques as citing a book or journal article. To make it even easier, the UK Data Service helps its users by providing pre-formatted data citations with all its collections.
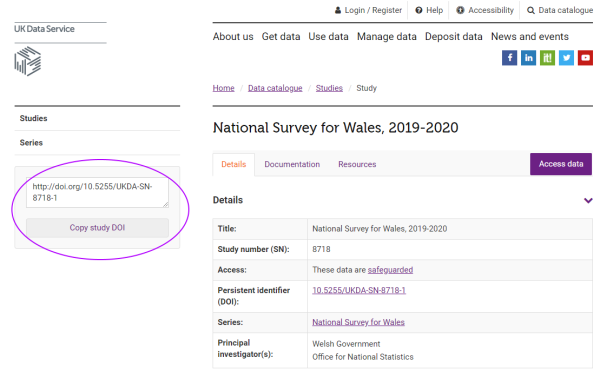
You can find our guidance on citing data on YouTube.
Citing data using persistent identifiers (such as DOIs) supporting verification and attribution of research, helps people to understand the impact of the research and offers the realisation and demonstration of efficiencies through re-use.
If researchers and research managers use these persistent identifiers then data owners can see more easily that their data is being used, which should make it more likely that more data is offered to the UK Data Service in the future.
It will also help even more of the components of impact case studies be persistent in the longer term. For a quick overview, see our top ten tips to citing data. So please #CiteTheData as you finalise your impact case studies for REF 2021.
Victoria Moody is Co-investigator and Deputy director of the UK Data Service.
