
Louise Corti, the UK Data Service’s Director of Collections Development and Producer Relations, discusses progress made in 2016 in qualitative data archiving and data exchange.
Louise informs us, “as we head into a new year, I am taking this opportunity to recap on some significant progress made in 2016 in the practice of qualitative data archiving and data exchange. These are topics that are dear to my heart, perhaps even obsessively so!”
This past year has bought to fruition five really positive outcomes in qualitative data. The first is that the UK Data Service has reached the 1000 mark for the number of unique qualitative and mixed methods data collections; we can boast the largest collection in the world on a national scale. The second is the praise received for training in the sharing and archiving of qualitative data to existing survey archives around the world. The third is the launch of the open access Special issue of Sage Open on Digital Representations: Re-Using and Publishing Digital Qualitative Data edited by Louise Corti, Nigel Fielding and our own Libby Bishop, bringing together a collection of articles with a social science or social historical perspective that present the current state of the art in the field of re-using and publishing digital qualitative data. Fourth, is real progress on the quest for data export and exchange from Computer Assisted Qualitative Data Analysis Software (CAQDAS) packages, pioneered by me and colleagues since the late 1990s, now being addressed collectively by the software vendors themselves. Finally, the great news that a small working group has been set up with Europe’s leading experts on CAQDAS to prepare and promote open teaching datasets from the UK Data Service for teaching the software, data management and archiving, and qualitative research methods.
One: 1000 collections and rising!
We have steadily built our collection of qualitative and mixed methods data over a period of 22 years and it has now reached over 1000 collections – 1027 to be precise – as I write. We are proud to be able to boast the largest collection of accessible qualitative data – derived from primary research – in the world, with our colleague European data services building their own collections of qualitative data (figures from Dec 2016).
The national data (survey) archives – qualitative data holdings
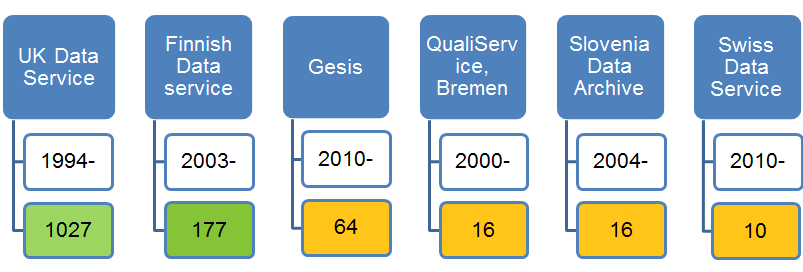
We developed Qualidata in 1994 and over 22 years this small archiving initiative set up the sociology department at the University of Essex grew and matured into a fully fledged core strand of UK Data Service/UK Data Archive business. Qualidata pioneered and piloted a systematic national approach to qualitative data sharing and archiving, a model that is now promoted and used across the world as survey archives begin to acquire and handle qualitative data. Our funders, ESRC can be very proud that through their continued support for qualitative data sharing and other initiatives like Timescapes, plus an inclusive Research Data Policy, the UK can now boast the largest and most diverse collection of data in the world.
Let us not also forget the added-value support and training services to accompany these data. I might go as far as to say that we pioneered the very concept of SAQD and also created commotion in ‘the literature;’ as scholars found a new opportunity to debate the pros and cons of sharing and reusing qualitative data. Yes, Qualidata had its fair share of critics in the 1990s but, as they say, there is no such as thing as bad publicity, and I’m inclined to agree! I see other countries survey archives engrossed in the same debates, as I am often asked to consult on the formation of new qualitative data initiatives. Yes, in the UK we have been there and done that, but honestly, I advise, do bear with it. All will redeem itself.
Here at the UK Data Service we have qualitative data fully integrated into every day business and a handful of specialists in house amongst our 70 staff to deal with data processing, metadata, specialist advice on consent and ethics, training and creating user resources. Of course, there are enormous benefits to a shared infrastructure, with all data flowing in under one roof, and our processing staff are more than happy to work with survey and qualitative data side-by-side. The majority of our qualitative data come in via our self-deposit system, ReShare, as a result of the ESRC Research Data Policy. Reshare data can be identified by the Study Number prefix, which is 85XXX.
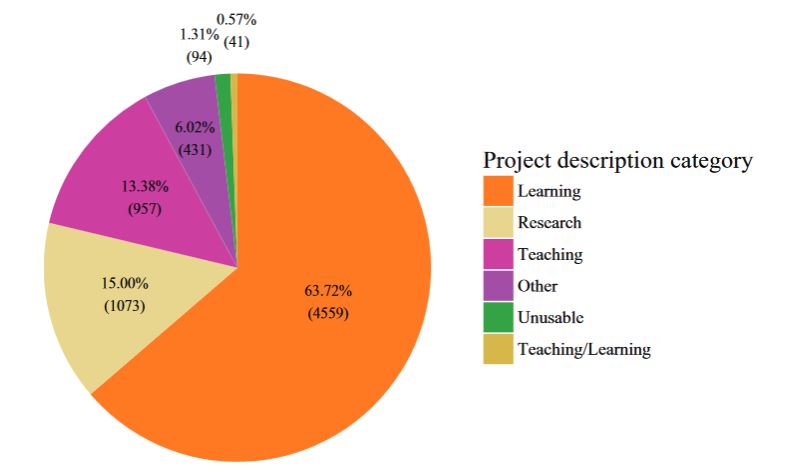
Libby Bishop’s recent findings illuminate the profile of usage of these qualitative data holdings, with over two thirds using data for teaching and learning across all instructional levels, from undergraduate to postgraduate. Teaching with data in our collection is a topic I will return to briefly later.
Re-use purposes of qualitative data downloaded from UK Data Service, 2002-2016 (Bishop and Kuula-Luumi, 2017)
Two: Success in training on archiving qualitative data
This year we have run training courses for survey archives on how to ingest, curate and disseminate qualitative data as part of core archive business, I have delivered half-day workshops at the Cape Town DataFirst and Taiwan Survey Research Data Archive, which have been very well-received. A training session is also booked in for the new Indian Social Science Data Service in Gandhinagar. In my training I emphasise that it is only a small leap that professional archives need to take to embrace the flow of qualitative data, as the majority of the workflow activities are identical to those for quantitative data. Our research data management team also routinely include qualitative data sharing in our training, as is the case for out ICPSR Summer school course, and it always is gratefully received.
Three: Launch of our Special Issue of Sage Open: Digital Representations: Re-Using and Publishing Digital Qualitative Data
I am also absolutely delighted to have completed the Digital Futures work, a project for which I was PI, funded by the ESRC in 2012, that aimed to: build a platform for publishing, presenting and searching the content of qualitative data; enable citation of these data at the data level; and to work with scholars to reuse data in the system and its citation features. Those of us who have worked as editors of journals will know that editing can take months and months of reminding and encouraging authors to finish; so I was relieved when our collection of papers as a special issue was finally published in the open journal, Sage Open, Digital Representations: Re-Using and Publishing Digital Qualitative Data. This collection of papers comprises five contributions with a social science or social historical perspective that present the current ‘state of the art’ in the field of re-using and publishing digital qualitative data. The articles address the use of digital sources in qualitative research in both research and teaching, charting types of use over the past 10 years, and looking forward to emerging practices and methods, such as the promise and potential that technological innovations can bring new ways of presenting and publishing qualitative research. Some of the papers make use of direct linking, allowing the reader to explore “live” data sources, offering an opportunity to see how research transparency might be operationalised in the presentation of qualitative findings and reporting. The papers reference major contributions to the literature, present stimulating debates on the topic and build on previously well-cited publications in which the editors have presented state-of the-art articles on secondary analysis of qualitative data, with contributions from:
- Myself and CAQDAS guru, Nigel Fielding on: “Opportunities From the Digital Revolution: Implications for Researching, Publishing and Consuming Qualitative Research“;
- Libby Bishop and Arja Kuuli-Luumi from the Finnish Data Service on: “Revisiting Qualitative Data Reuse: A Decade On“;
- Jon Lawrence of Cambridge University and Jane Elliott, CEO, ESRC on: “The Emotional Economy of Unemployment: A Re-Analysis of Testimony From a Sheppey Family, 1978-1983“;
- Florence Sutcliffe-Brown of Cambridge University on: “New Perspectives From Unstructured Interviews: Young Women, Gender and Sexuality on the Isle of Sheppey in 1980“;
- Maureen Haaker and Bethany Morgan Brett (current and former UK Data Service staff) on: “Developing Research-Led Teaching: Two Cases of Practical Data Re-Use in the Classroom”.
We hope that these papers will encourage the take up of robust data citation and scholars can see the great value in publishing qualitative data to increase transparency in the reporting of their findings. With readers now able to return directly to quoted extracts of data, situated in content within their ‘mother’ interview, we hope to encourage more good scholarly practice in both publishing and citing data.
Four: Qualitative data exchange: unlocking data locked up in software
I return to the still challenging issue of how to archive qualitative data in a non-proprietary and sustainable format that becomes ‘locked up’ in a bespoke commercial package during data analysis. Back in the early days of Qualidata we were offered data in proprietary format, like NUDIST, Atlas-ti and WinMax. Even now the new incarnations of these market-leading softwares use proprietary data formats; and they largely don’t talk to each other. With some new kids on the block and greater recognition of open source/open formats, new opportunities for us as data curators have arisen. The new generation of students all take for granted the use of computational software to handle data, and with the days of scissors and paper long gone for qualitative data analysis, getting value-added data in and out of multiple softwares is even more crucial.
In recognition of a lack of any standard way to exchange software between qualitative software, in 2006-2008 I led a grant from JISC entitled DEXT – Data Exchange Tools and Conversion Utlities which aimed to create an extensible data exchange standard for qualitative data. Starting with mapping all the major softwares key functionality at the time, we built a purposively extensible format that we termed QuDEX. This schema enables preservation of thematically coded and annotated data in a software neutral and archivable format; providing an opportunity for transport in and out of CAQDAS. Thanks to Arofan Gregory as our lead XML consultant, and our own Herve l’Hours as a data standards experts, we made use of W3C standards to create and publish as formalised and documented schema, QuDEx. A journal article on the development of QuDex by Corti & Gregory can be found in CAQDAS Comparability. What about CAQDAS Data Exchange? This is what lies behind our own publishing qualitative data system, QualiBank, skillfully crafted utilising an XML database – and millions of GUIDs – by our own in-house metadata guru, Darren Bell.
Though take up of the schema as an open XML data exchange format was not forthcoming by software vendors due to a number of factors: a lack of devolping opportunities for exchanging of coded data between competitor softwares, lack of focus on archiving as core functionality and programmatic challenges of building import and export tools. A number of other social science data archives have been interested in the schema and how it can be used to publish qualitative data using a Write Once, Read Many times approach. Disappointingly, much published oral history on the web is hard coded manually and not transferable to other publishing interfaces.
However, I am again thrilled (2016 – a year of data delight!) that the CAQDAS developers community has decided to embrace the need for an exchange format and have formed a working group to come up with it. The inter-University Dutch Platform for Qualitative Research Dutch, KWALON, and colleagues at Quirkos have helped nurture this developer-driven initiative, and further helped introduce QuDex work into the group to ensure that it gets reviewed, and wheels do not get unnecessarily reinvented. I completely support the idea that it is the developers who need to agree on some core baseline needs to move forward with import and export. And, of course, it’s never too late! At a recent Conference on The Future of QDA Software held at the Erasmus University in Rotterdam in August 2016, a major push to promote data exchange was launched. Conference Chair Jeanine Evers noted that such a standard could also be important for formatting data (watch the video of the conference discussion). Vendors recognise that enabling coded qualitative data to be widely shared and stored for secondary analysis is not only important for archival purposes, but also to make it easier for data to be brought in for analysis from the huge number of digital sources across the social sciences and digital humanities.
Coincidentally, at the same time this was coming to fruition in the early autumn of 2016, the Qualitative Data Repository (QDR) at Syracuse got some funding to host a workshop on archiving data from CAQDAS, in New York in October 2016, to which I was invited. I’ve been a consultant for QDR from its inception, with its focus on data collected from political science field work, and have been really impressed with the stepwise scaling up of its service under the leadership of Professor Colin Elman, Director of the Center for Qualitative and Multi-Method Inquiry and the Qualitative Data Repository at Syracuse. At this meeting a few of the software vendors attended and some very useful discussions were held on the challenges of archiving research projects that had been analysed in CAQDAS software, thus returning to the topic above. I proposed that we could usefully separate the idea of true data exchange between softwares from simple export from a package to a data archive, as the latter is likely much easier. Here at the UK Data Service we already offer advice to researchers on what to keep from CAQDAS projects, and also authored stand alone step by step modules and instructional exercises on data handling in NVIVO9. Examples include keeping:
- Clean transcripts, anonymised where needed (any flavour, minimal to Jeffersonian);
- Speaker tags and some header information (including a transcription template );
- A data list – data item by classification /category (finding aid, we provide a data list template) and export to quantitative data where possible
- Final coding frame – any open format;
- Date-ordered time-stamped researcher memos, for example, set out like a research diary.
The meeting agreed that even a simple prompted checklist of what to keep from a qualitative project undertaken using CAQDAS could be really helpful.
Five: Making the most of UK Data Service open datasets for teaching CAQDAS and research methods
Another great outcome of the New York meeting I attended was the formation of a small European-based group, who have already worked together over the past 15 years, to look at making wider use of archived qualitative data held by the UK Data Service for teaching of CAQDAS and teaching qualitative research methods, and to connect the two together. The UK Data Service is currently reviewing its 1027 qualitative and mixed methods collections to see which used CAQDAS in their analysis; the theme and pedagogic appeal of the research; the complexity of the study design and data capture; and which might be most suitable for open access teaching data resources.
I am really looking forward to 2017 as I see that qualitative data, management and sharing is now firmly planted on the international agenda.