
 Our own Libby Bishop, Manager of Producer Relations: Research Ethics here at the UK Data Service, and Dr Felix Ritchie, Associate Professor in Applied Economics at Bristol Business School discuss the ethical, legal and technical challenges presented by big data.
Our own Libby Bishop, Manager of Producer Relations: Research Ethics here at the UK Data Service, and Dr Felix Ritchie, Associate Professor in Applied Economics at Bristol Business School discuss the ethical, legal and technical challenges presented by big data.
Big data come in a variety of forms, such as administrative data, transactional data and data generated by social media. All present challenges from ethical, legal and technical perspectives.
Are the data personal? Or sensitive? Was consent obtained? Is it even possible to obtain consent? Have the data been de-identified? What about identification after the data have been linked? Would your opinion as to what constitutes an ‘ethical’ use of data be shared by the data subject? If not, does it matter?
Various tools and checklists are proliferating on the internet promising to solve the challenge of the ethical use of big data. But ethical data use cannot be accomplished by running through a checklist. That said, data projects are not ethics seminars either. A balance must be struck.
One starting point is to consider the contemporary meanings (and myths) about privacy, for example, the idea that privacy is of no importance to millennials because they place a large amount of personal information on the web. It is important to question such assumptions. Indeed, the data do not suggest that younger people are significantly less concerned about privacy. A Special Eurobarometer 431 survey on Data Protection, published in June 2012, examined the views of EU citizens about issues surrounding data protection. In a question related to privacy settings on online social networks, 42% of respondents had never attempted to alter the privacy settings of their personal profile from the default settings on an online social networks. Examining the reasons behind why those respondents had decided not to alter these privacy settings, 29% of those in the 15-24 age group said it was because they “are not worried about having personal data on an online social network.” However, 22% of those in the 40-54% age group also cited this as a reason (with 19% and 17% of respondents in the 25-39 and 55+ age groups respectively sharing this view).
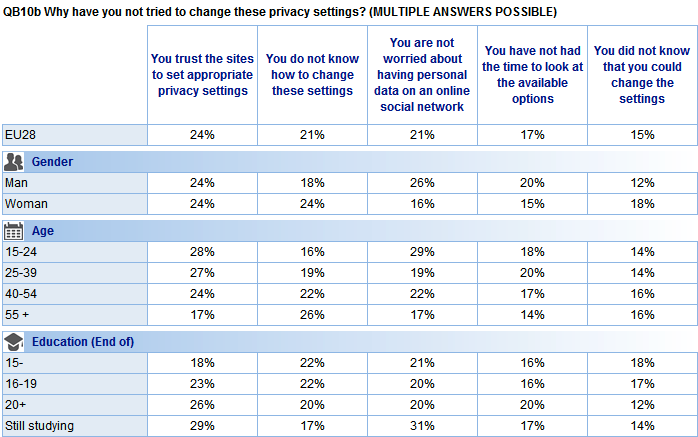
Base: Respondents who have not tried to change their default privacy settings (n=6,373 in EU28)
Source: European Commission: Special Eurobarometer 431 (Data Protection). March 2015. TNS Opinion & Social Brussels; DOI: 10.2838/552336
Assessing new innovations for protecting privacy
Certainly, concerns about privacy and digital data arose long before big data, and data custodians in both the public and private sectors—governments, repositories, companies—have relied on a number of practices in order to protect personal data:
- anonymisation (or de-identification)
- obtaining informed consent
- regulation of access to data
Changes in the data landscape present new challenges when relying on such practices to uphold rights to privacy. The systems and tools for analysing big data are becoming more powerful, with new algorithmic methods of analysis that raise questions over the effectiveness of existing techniques of anonymisation and de-identification. As Narayanan and Felton 2014 found, there is no “silver bullet” option out there. Once we recognise this, we can move away from thinking in black-and-white terms and focus on minimising (but not eliminating) risks and balancing risks with the benefits to society from the use of these data.
There are also practical issues to consider. Procedures for obtaining informed consent are unfeasible for many forms of new data – for example, how can one say that consent for an undefined future purpose can be truly considered as being “informed”? Surely to be ”informed” implies some knowledge of what will happen to that data. Furthermore, the growing capacity to link diverse data sources also presents challenges for the mechanisms that control access to data (Barocas and Nissenbaum 2014).
The problems with the processes of anonymisation, consent and access are not restricted to big data, but as Barocas and Nissenbaum put it, big data has transformed the “fault lines” in existing practices into “impassable chasms” (Barocas and Nissenbaum 2014, 45). The problems that big data brings to light extend beyond legal or technical inconveniences and reveal fundamental conceptual challenges.
Find out more
Libby and Felix explored the considerations of confidentiality, privacy and ethics in the field of big data, as one part of a session on ‘Secure access protocols for big data’ at the Essex Big Data and Analytics Summer School 2015. This session aimed to provide practical guidelines on tackling these issues, for anyone thinking of analysing (potentially) confidential data. They have also written comprehensively on the topic. Details of Libby’s publications can be found on her UK Data Archive staff page, while information about publications authored by Dr Felix Ritchie is available on the University of the West of England, Bristol staff profile pages.
References:
Barocas, S. and Nissenbaum, H. (2014) Big Data’s End Run around Anonymity and Consent, in J. Lane et al. (eds) Privacy, Big Data and the Public Good. Cambridge University Press. Chapter DOI: https://dx.doi.org/10.1017/CBO9781107590205.004
Narayanan, A. and Felton, E. (2014) No silver bullet: de-identification still doesn’t work, https://randomwalker.info/publications/no-silver-bullet-de-identification.pdf.