 We thought we’d celebrate #LoveDataWeek and four years of the #DataImpactBlog with a look back over some of the varied posts from the last four years.
We thought we’d celebrate #LoveDataWeek and four years of the #DataImpactBlog with a look back over some of the varied posts from the last four years.
This blog showcases the impact of the UK Data Service and the people who create, manage and use the data it makes available in learning, teaching, research and policy, as part of our wider focus on impact funded by the Economic and Social Research Council (ESRC). We’re welcoming #LoveDataWeek with a recap of some posts from the last four years since our Director, Matthew Woollard, posted a welcome to the blog back in 2015. The posts show the breadth of what we do here at the UK Data Service and the growth of a vibrant data impact community.
We’ve posted content from a range of writers who’ve been creating, managing and using some of the wonderful data assets we make available, in the UK and internationally to understand the pressures, priorities and changes in people’s lives over time and guiding policy development. What themes have emerged and what’s changed in the data impact space?
Data creation
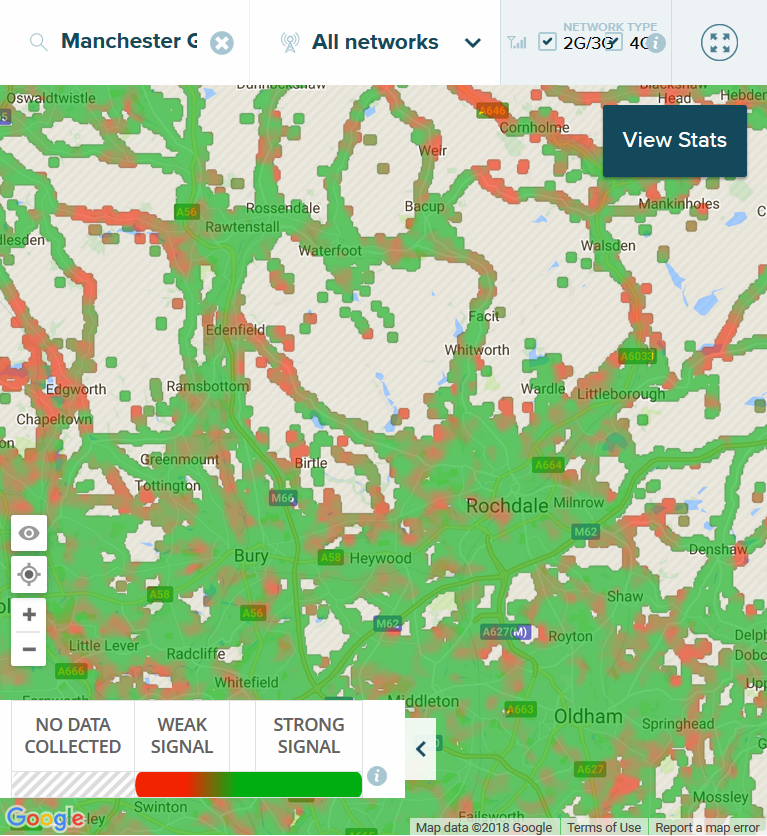
In January 2018, Oliver Duke-Williams, Senior Lecturer in Digital Information Studies in the Department of Information Studies at UCL and Co-Investigator at the UK Data Service, discussed the considerable interest within UK statistical agencies and in the wider community, in the use of administrative data to wholly or partially replace the decennial census. Oli noted that the logic for this approach is clear:
“…taking a census is an expensive operation and the data captured become increasingly out of date as time moves on.”
Open signal: 3G and 4G mobile phone coverage map
He highlights the issues with proposals for viewing the use of mobile phone data as a compete replacement for the journey to work data collected by a census.
In a post from October 2015, Anne Solon, data manager for Young Lives, who works with Young Lives research partners to coordinate the process of survey design, piloting, training of field staff, data collection, data entry and data management, discussed the challenge of tracking in a longitudinal study of children. Young Lives is an international study of childhood poverty, involving 12,000 children in 4 countries over 15 years.
![]()
Young lives is led by a team in the Department of International Development at the University of Oxford in association with research and policy partners in the 4 study countries: Ethiopia, India, Peru and Vietnam.
Data curation and management
Last September, Louise Corti, Director of Collections Development and Data Publishing for the UK Data Service explored research reproducibility in qualitative research. Louise noted how, in quantitative methods, reproducibility is held as the gold standard for demonstrating research integrity. While qualitative research reproducibility has been questioned in the past, it has been protected from the recent transparency agenda.

Louise concluded that
“if journals seek to extend their reproducibility agenda to qualitative research, they could usefully start by encouraging process transparency while not mandating replicability.”
Data skills
In October 2017 Louise Corti and Scott Summers held an event: Supporting civil society organisations to gain insights and develop impact from data which focused on opportunities and challenges for professionals working with administrative, monitoring or evaluation data in civil society organisations (CSO).

Attendees from a range of charities and civil society organisations took the opportunity to meet to explore ways of managing and sharing data ethically and discussing how data can be used to demonstrate the impact of their activities.
In another skills-focused post from Louise reported back from the course, Encounters with Big Data: An Introduction to using Big Data in the Social Sciences, held in Cape Town, South Africa in 2017.
Data access
In August 2018, James Scott and Christine Woods, Senior User Support and Training Officers (Secure Access Training) at the UK Data Service, introduced us to the Safe Data Access Professionals (SDAP) Working Group and the work the group is doing to as a way to share experience and learn from each other. James and Christine introduced the SDAP website – an online hub for information on SDAP events, guides and resources etc. The group’s first publication – The Safe Data Access Professionals (SDAP) Competency Framework is available and you can get in touch with the Group here.
Open data
Back in November 2016 we held one of our events #DataImpact2016 focused on all things data impact in Glasgow. Bill Roberts, founder of Swirrl, linked open data enthusiast working on PublishMyData, reprised his presentation at #DataImpact2016 where, Bill explained
“what we need in the data economy now is our own industrial revolution. That means specialisation and automation: building components that can be exploited by others and agreeing standards so that different players can interact and combine their efforts. At each stage in the value chain we need to create a market where innovation and competition can thrive.”
Here’s the blog post.

Photo credit: “Engine” by fatedsnowfox
Data ethics
In March 2017, Libby Bishop, our former Producer Relations Manager and expert on the ethics of re-using data and informed consent at the UK Data Service, discussed the ethical considerations and the importance of setting standards when using social media data. Libby focused on how
“the analysis of social media data presents a number of challenges, including ethical and legal ones associated with consent and anonymisation.”
Libby pointed us to our Big data and data sharing: Ethical issues guide, which covers issues in anonymising Tweets because Twitter’s Terms and Conditions prohibit modifying content. Although Twitter may be viewed as a public platform, survey analysis by the Social Data Science Lab showed that Tweeters did not want their content used, even for research, if they were identifiable.
Data use
In one of our early posts from March 2015 on data use, Jennifer Mindell, Reader in Public Health in the Department of Epidemiology & Public Health at UCL, discussed the role of the Health Survey for England in informing obesity policy. The UCL team were responsible for the analyses which identified obesity as one of the main risk factors behind the differences in prevalence of multiple lifestyle risk factors by age and by socio-economic position.
In a post from this January, Alasdair Rae discussed the use of a variety of data sources, including Census data on travel to work and employment status, along with the stories of the people affected, to explore the reality of using public transport to access work from poorer areas of the UK. Alasdair focused on how in 2016 the Department for Work and Pensions suggested that jobseekers should look for jobs up to a 90 minute commute away. In a tweet about this, the Department suggested that jobseekers could ‘travel, for fun and for profit’. In a report for the Joseph Rowntree Foundation with colleagues at Sheffield Hallam University, the team explored the topic in more depth and found that for residents of low-income neighbourhoods the geography of employment opportunities is often highly restricted due to poor transport.
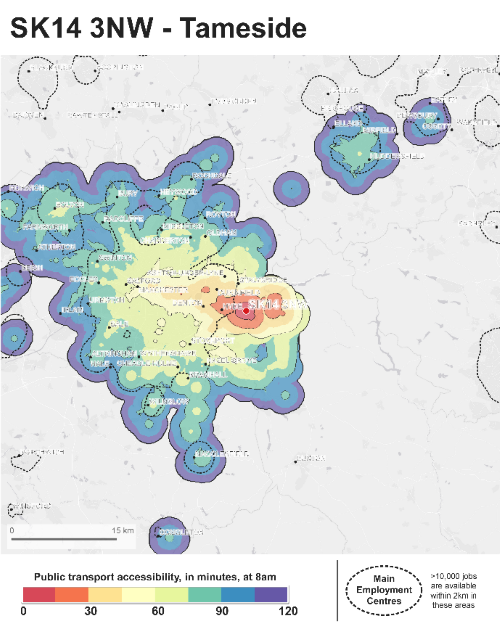
The team concluded that the effect of poor transport is not surprising, yet too often overlooked.
Last October, Dr Milena Buchs Associate Professor in Sustainability, Economics and Low Carbon Transitions at the University of Leeds presented her research using Understanding Society data to assess whether people with health challenges might find it difficult to save energy. Milena also found that people with health challenges might have travel needs that they find difficult to meet owing to financial and mobility constraints. She concluded that public transport systems need to be made more accessible and affordable.
Data policy
In November 2015, Matthew Woollard our Director, presented his response to the Commons Science and Technology Select Committee to examine the opportunities and risks of ‘big data’. Back in July 2015, the Commons Science and Technology Select Committee announced an inquiry to examine the opportunities and risks of ‘big data’. The inquiry focused on whether the government is doing enough to allow entrepreneurs to benefit from the big ‘data revolution’, and to protect the rights of data subjects.
Among Matthew’s responses were that
“funding for data service infrastructure needs to be provided on a more sustainable basis. In order to maximise the reuse potential of any type of data, it needs to be managed effectively through the whole of the data life-cycle, and if this management can be centralised, harmonised controls (covering consent, privacy rights, the maintenance of ownership, (rights) and research ethics/integrity) can be applied consistently, and independently from either the data controller or the data users“
You can find out more about The Big Data Dilemma and read the reports and responses here: https://www.parliament.uk/business/committees/committees-a-z/commons-select/science-and-technology-committee/inquiries/parliament-2015/big-data/
Data citation
Back in July 2015 Victoria Moody, UK Data Service Deputy Director and Director of Impact blogged about the launch of our #CiteTheData campaign, welcoming the publication of The Metric Tide – a report on the independent review of the role of metrics in research assessment and management, chaired by Professor James Wilsdon.
In particular, we welcomed Recommendation 13 that
“The use of digital object identifiers (DOIs) should be extended to cover all research outputs. This should include all outputs submitted to a future REF for which DOIs are suitable, and DOIs should also be more widely adopted in internal HEI and research funder processes. DOIs already predominate in the journal publishing sphere – they should be extended to cover other outputs where no identifier system exists, such as book chapters and datasets.”
The citation of research data (and metadata) can support the understanding and promotion of research impact through the tracking of the use of data in research and on into policy and product development, influencing decisions about public and commercial spending and service provision.
In autumn 2018 we extended our #CiteTheData campaign, timing it with the news that 11 national research funding organisations, (including UKRI) with the support of the European Commission including the European Research Council (ERC), announced the launch of ‘cOAlition S’, an initiative to make Open Access to research publications a reality, where:
By 2020 scientific publications that result from research funded by public grants provided by participating national and European research councils and funding bodies, must be published in compliant Open Access Journals or on compliant Open Access Platforms.
The UK Data Service already supports a #Coalition S’ compliant data infrastructure, part of a European network where rich and detailed metadata can be harvested for data sharing through the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH).

#CiteTheData, aims to improve the citation of data, in the spirit of Plan S. Our latest blog about the #CiteTheData campaign is here.
Ideas and contributions
We welcome contributions to the blog from a range of voices and opinions. If you would like to contribute or have ideas for the blog, please contact the blog editor via ukdsimpact@jisc.ac.uk or tweet @UKDSImpact. You can also get more of an idea about writing for the blog here.

And remember, always #CiteTheData.
About the author
Dr Victoria Moody is the UK Data Service Director of Impact.